

最近 AI 圈出了个大事儿,不少的AI模型生成的代码,它生成的假 URL 和假代码,竟然被黑客当成了攻击武器!
我刚开始都不信,直到看到真实案例,才发现这事儿真的太离谱了!
来来来,今天咱们就好好聊聊这个 AI 代码幻觉的问题,看看黑客是怎么利用它攻击的,又该怎么防范。
【正文】兄弟们,先给你们讲个真实案例!
去年 3 月和 9 月,安全研究员发现 AI 代码助手会编造程序包名称。
然后呢?
恶意人员就利用这一特性,创建恶意软件包,并按 AI 幻想出的包名称命名。
接着把这些恶意包上传到包注册表或索引发行。
当 AI 代码助手再次幻想出该名称时,开发者安装依赖和执行代码流程就会运行恶意软件!
这波操作我给满分!简直是教科书级别的利用漏洞!
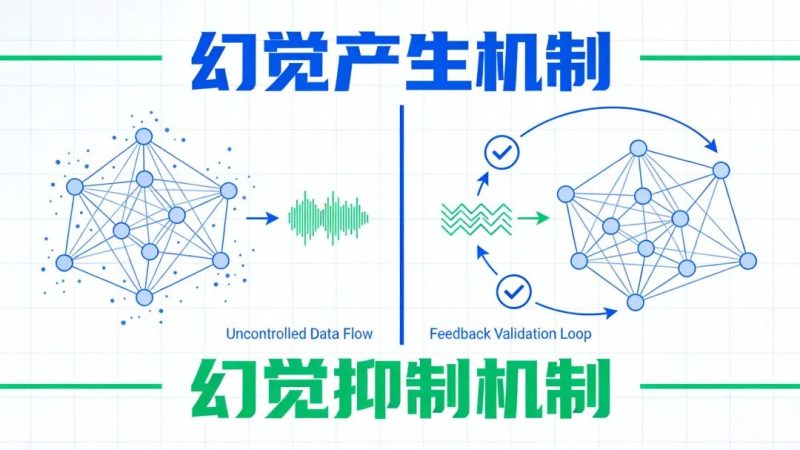
那 AI 为什么会产生代码幻觉呢?
简单说就是 AI 代码助手生成不存在的软件包、函数或 URL 等错误内容。
最新研究显示,商用 AI 模型平均会建议 5.2% 的不存在软件包,而开源模型这一比例更是高达 21.7%!
这比例也太吓人了吧!
那 AI 为什么会产生代码幻觉呢?
主要有这么几个原因:
首先是模型架构的局限性。
大语言模型本质上是概率生成器,它们通过学习大量文本数据中的统计规律来生成内容。
当遇到不确定的问题时,模型不会说 “我不知道”,而是会根据训练数据中的模式生成最可能的答案。
就像你考试遇到不会的题,也会蒙一个看起来最像正确答案的选项一样。
其次是训练和评估体系的问题。
现行的模型评估标准奖励了模型的猜测行为,而不是鼓励它承认知识局限。
模型被训练成要给出 “看起来合理” 的答案,而不是 “正确” 的答案。
这就导致模型在不确定的时候,更倾向于编造一个听起来合理的答案,而不是说 “我不确定”。
还有就是代码世界的复杂性。
代码世界里有无数的库、函数和 API,模型很难记住所有细节。
当遇到不熟悉的问题时,模型会根据已有的知识进行 “创造性” 扩展,从而生成不存在的内容。
就像你让一个只学过 Python 基础的人去写深度学习代码,他可能会编造一些听起来很专业的函数名。
那不同大模型的幻觉率有什么区别呢?
这个区别可大了去了!
商用模型建议的不存在软件包比例约为 5.2%。
而开源或开放可用模型的这一比例高达 21.7%!
这意味着使用开源模型的开发者面临更大的安全风险。
那黑客是怎么利用 AI 代码幻觉进行攻击的呢?
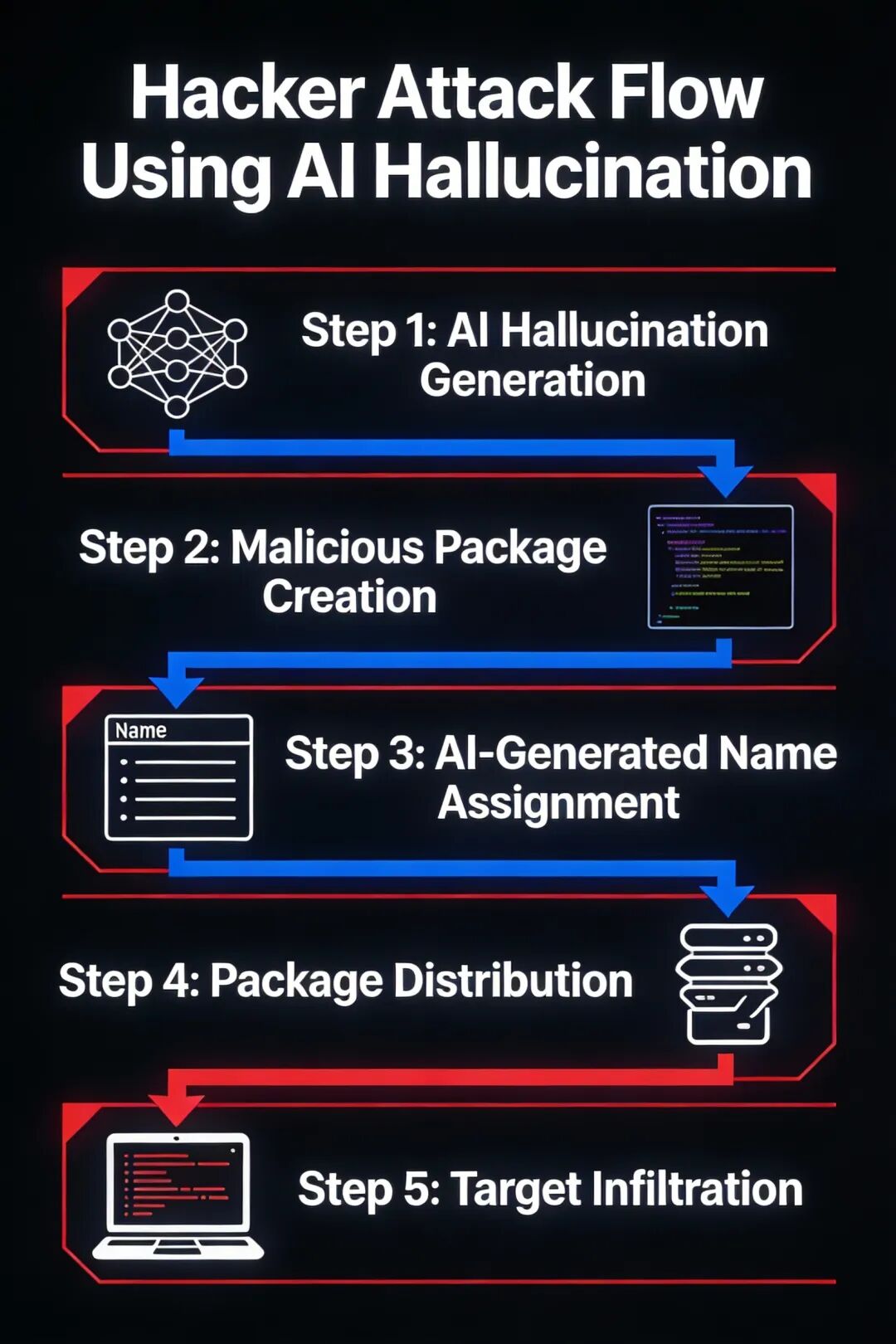
他们的攻击流程一般是这样的:
第一步,收集 AI 代码助手生成的不存在的包名称。
第二步,创建恶意软件包,并使用这些不存在的包名称。
第三步,将恶意包上传到软件包注册表。
第四步,等待 AI 代码助手再次生成这些不存在的包名称。
第五步,当开发者按照 AI 的建议安装这些包时,就会执行恶意代码!
这波操作是不是很骚?
那我们该怎么防范呢?
别急,我给你们总结了几个实用的方法:
首先,验证所有 AI 建议。
在使用 AI 建议的任何库、函数或 URL 前,务必通过官方文档或可靠来源进行验证。
不要盲目相信 AI 的建议,特别是那些听起来很新、很专业的库。
其次,优先使用商用模型。
虽然商用模型也存在幻觉,但概率远低于开源模型。
对于关键项目,建议使用经过严格测试的商用 AI 代码助手。
第三,实施依赖审查。
建立依赖包审查机制,特别是对于新引入的依赖,要检查其来源和历史版本。
可以使用一些工具来帮助你检查依赖包的安全性。
第四,保持警惕。
对于听起来过于 “完美” 或不常见的库名称,要特别警惕。
AI 往往会生成听起来专业但不存在的名称,比如 “ultra-fast-json-parser”。
第五,及时更新你的 AI 助手。
AI 模型一直在不断改进,新版本通常会有更低的幻觉率。
所以,记得及时更新你的 AI 代码助手,享受最新的改进。
那有没有什么技术手段可以减少 AI 代码幻觉呢?
当然有!
最近有不少研究成果,比如清华团队的 “先验证,再作答” 方法。
他们提出了一种新方法,就是先给模型候选答案让它验证,再生成最终答案。
这种方法能减少粗心错误、促使逻辑反思、纠正思路偏差。
还有 RAG 技术,也就是检索增强生成。
RAG 技术通过架构范式转移,系统性地解决大模型幻觉与知识瓶颈问题。
传统大模型被设计成 “全知体”,试图记住所有知识;而 RAG 模型则将大模型转变为 “检索者”。
在生成答案前,它会先从外部知识库中检索相关信息,确认建议的库或 API 是否真实存在。
还有一种叫 RAS 的新范式,也就是检索 – 分析 – 生成。
它通过知识结构化来解决幻觉问题。
传统 RAG 方法处理非结构化文本容易导致幻觉和推理困难,而 RAS 则通过将知识结构化,让模型能够更好地理解和使用知识。
那我们普通开发者该怎么通过提示词来减少 AI 代码幻觉呢?
这里给你们几个实用的提示词技巧:
第一,明确要求 AI 提供真实存在的库和 API。
比如你可以说:”请提供真实存在的 Python 库,用于处理 JSON 数据,不要编造不存在的库。”
第二,要求 AI 提供官方文档链接。
比如:”请提供用于数据可视化的 Python 库,并附上官方文档链接。”
第三,要求 AI 解释推荐理由。
比如:”请推荐一个用于机器学习的 Python 库,并解释为什么推荐它,以及它的主要特点。”
第四,要求 AI 验证推荐内容。
比如:”请推荐一个用于网络请求的 Python 库,并验证它是否存在于 PyPI 上。”
第五,使用更具体的问题。
比如不要问 “如何处理 JSON 数据”,而是问 “Python 中处理 JSON 数据的标准库是什么?”
这些提示词技巧都能有效减少 AI 代码幻觉的产生。
【总结】总的来说,AI 代码幻觉是当前 AI 代码生成技术面临的一个重要挑战。
它不仅影响开发效率,还带来了严重的安全风险。
不过,好消息是,研究人员和工程师们已经在这个问题上取得了一些突破。
作为程序员,我们自己也要保持警惕,不要盲目相信 AI 的建议,要养成验证的好习惯。
毕竟,安全第一嘛!
相信随着技术的不断进步,AI 代码幻觉问题会得到越来越有效的解决。
更多阅读:










暂无评论内容